【前編】AIとブロックチェーンデータの融合における今後の考察
本レポートについて
本レポートは、Footprint、Future3 Campus、HashKey Capitalが共同で発表したものの要約です。
今話題のAIとWeb3データの可能性や今後の展望など興味深いテーマとなっているので、ぜひご確認下さい。
GameFiデータ本レポートの内容

大規模言語モデル(LLM)の進化により、AIとWeb3の融合への注目が高まり、新たなアプリケーションパラダイムの到来を予感させる。
本レポートでは、AIがブロックチェーンデータのユーザー体験と生産性をどのように向上させるかを探る。
キーポイント
- Web3データ特融の課題をAIで解決
- 業界の初期段階とブロックチェーン技術のユニークな特性により、Web3データはデータソース、更新頻度、匿名属性などいくつかの課題に直面している。AIによってこれらの課題を解決することが、話題の中心となっている。
- LLMの利点
- スケーラビリティ、適応性、効率改善、タスク分解、アクセシビリティ、従来のAIと比べた使いやすさなどの利点を持つLLMはブロックチェーンデータのエクスペリエンスと生産性を向上させる道を開く。
- LLMとブロックチェーンの相性
- LLMのトレーニングには、大量の高品質データが不可欠である。豊富なバーティカル・ナレッジとオープンに利用可能なデータを持つブロックチェーンは、LLM学習教材の貴重なソースとなる。
- 生産効率の向上
- LLMはブロックチェーンデータの生産を促進し、価値を高める役割も担っており、これにはデータクレンジング、ラベリング、構造化データ生成などのタスクが含まれる。
- LLM活用時の注意
- 注意しなければならないのは、LLMは特効薬ではないということだ。特定のビジネスニーズに基づいて適用する必要がある。LLMの高い効率性を活用することと、結果の正確性を確保することのバランスを取ることが重要である。
AIの歴史
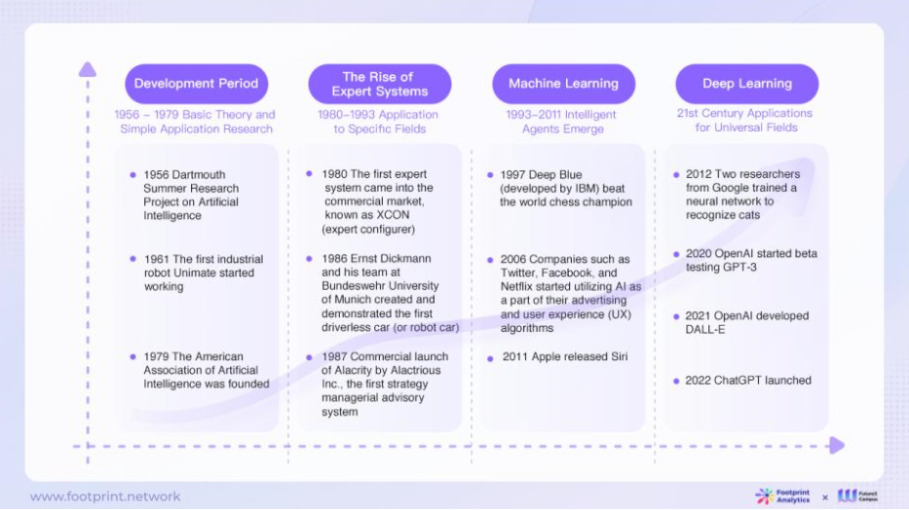
AIの歴史は1950年代にまで遡る。
1956年以降、AIに注目が集まり、専門領域の課題に対処するために設計された初期のエキスパートシステムが徐々に開発された。
その後、機械学習の登場によってAIの応用範囲が広がり、さまざまな産業で広く利用されるようになった。
そして今日、ディープラーニングと生成AIの爆発的な普及により、無限の可能性が開かれ、その一歩一歩が、より高いレベルの知見と広範なアプリケーションを追求するための絶え間ない挑戦と革新に彩られている。

2022年11月30日、ChatGPTのデビューによりAIがユーザーフレンドリーで効率的な方法で人間と対話できる可能性が初めて示された。
このデビューにより、人工知能に関する話題は大きなものとなる。
またその後もAnthropic(アマゾン)、DeepMind(グーグル)、Llama(Meta)など、大手が次々にAIの開発を行い様々な生成AIモデルへの関心を高めた。
同時に、さまざまな業界の専門家たちが、AIがそれぞれの分野でどのように進歩をもたらすかを積極的に模索し始めた。
中には、AI技術を組み合わせて業界内での差別化を図り、領域横断的なAIの融合をさらに加速させている企業もある。
Web3とAIの融合
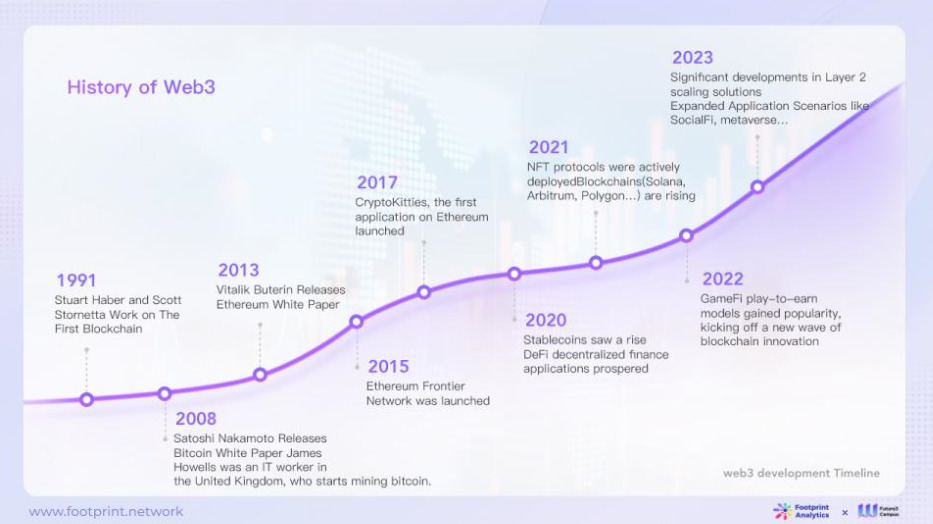
Web3のビジョンは、金融システムの変革から始まるもの。
特にブロックチェーン技術は、価値の伝達やインセンティブを再構築するだけでなく、リソースの割り当てや分散化を促進することで、こ目標を達成するための強固な技術として機能している。
2020年の時点で、ブロックチェーン投資会社のFourth Revolution Capital(4RC)は、ブロックチェーン技術とAIの統合を予見し、金融、ヘルスケア、電子商取引、エンターテイメントなどのグローバルなセクターの分散型変革を想定していた。
またAIとWeb3の融合は、2つの重要な側面を中心に展開する。
- 2つの側面
- 生産性とユーザー体験の向上にAIを活用
- 従来のアプローチでは解決できなかった課題に取り組み生産効率を高める
AIとWeb3の融合を模索する方向性としては、現在以下のようなものが行われている。
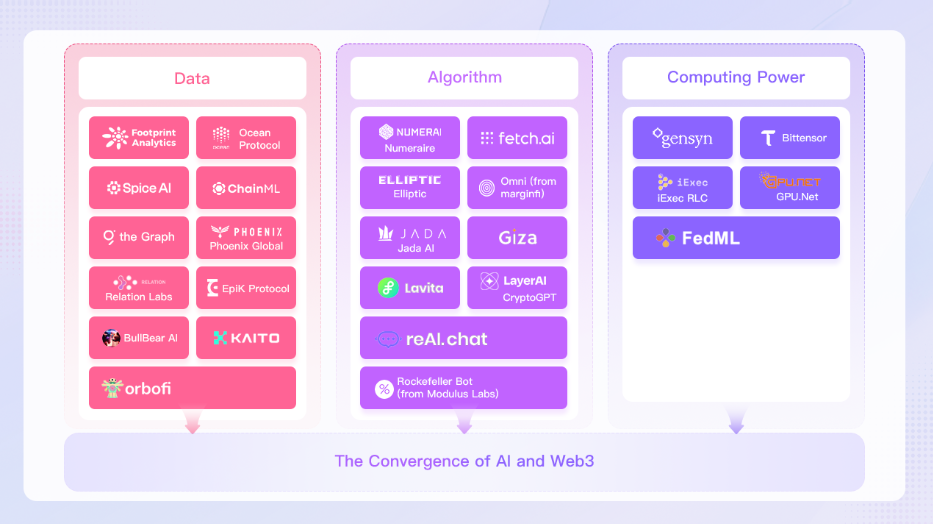
データ
ブロックチェーン技術は、モデルデータの保存、プライバシー保護のための暗号化記録の提供、モデルで使用されるデータの出所と使用の文書化、データの真正性の検証に使用されている。
AIはブロックチェーンに保存されたデータにアクセスし検証することで、モデルのトレーニングや最適化のための貴重な洞察を引き出すことが可能だ。
同時に、AIはデータ生産ツールとして機能し、Web3のデータ処理の効率を高めることができる。
アルゴリズム
Web3のアルゴリズムは、AIに対しより安全で信頼性が高く、自律的に制御された計算環境を提供する。
それらはAIシステムの暗号化保護を提供し、モデルパラメータ内にセキュリティ対策を埋め込むことで、悪用や悪意のある活動を阻止することが可能だ。
AIはWeb3のアルゴリズムと対話し、タスクを実行し、データを検証し、スマートコントラクトを通じて意思決定を行うことができる。
同時に、AIのアルゴリズムはより賢明で効率的な決定とサービスを提供することでWeb3に貢献するだろう。
コンピューティングパワー
Web3の分散リソースは、AIに高性能な計算能力を提供するだろう。
AIはこれらのリソースをモデルのトレーニング、データ分析、予測に使用する。
計算タスクを複数のネットワークノードに分散することで、AIは計算速度を加速し、より大きなデータセットを管理することが可能だ。
この記事では、Web3データの処理生産性とユーザー体験を向上させるためにAI技術を使用することに焦点を当てる。
Web3データの状況
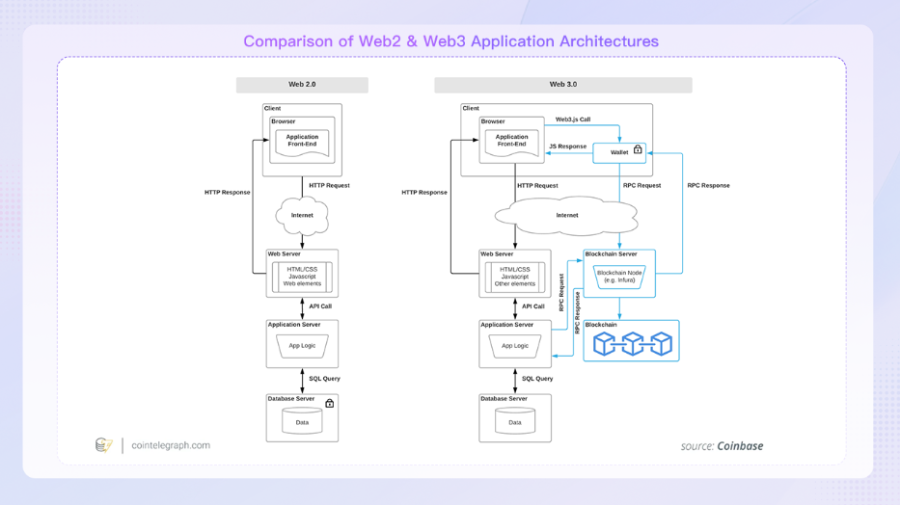
※Web2とWeb3のアプリケーションアーキテクチャの比較
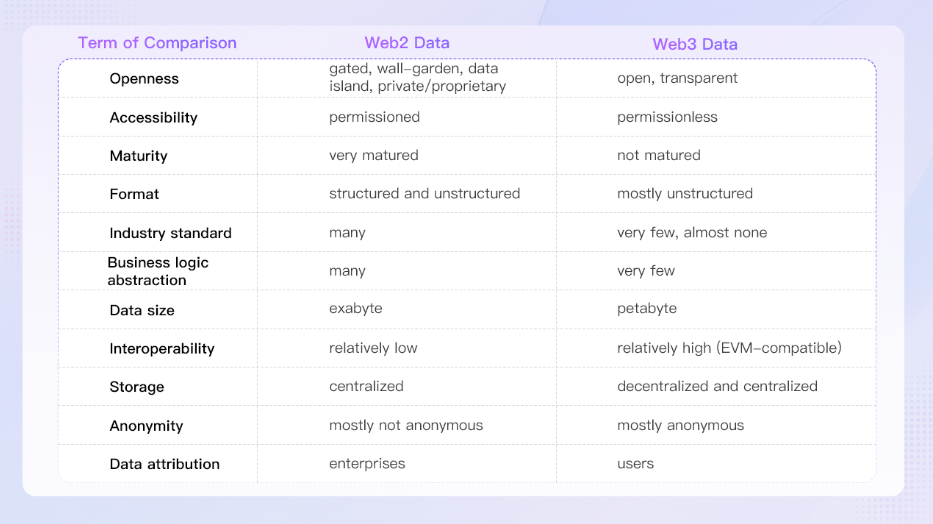
Web3データはWeb2データに比べ、多くの情報を引き出すことができる。
これはWeb2とWeb3のアプリケーションアーキテクチャの違いが大きなものとなっており、Web3データの方がよりオープンで広くアクセス可能となっている。
主に非構造化データで構成され、標準化はほとんど行われておらず、ビジネスロジックの抽象化も比較的単純化されている。
Web3データはWeb2データより規模は小さいが、EVM互換性など高い相互運用性を提供する。データは分散型でも集中型でも保存でき、ユーザーのプライバシーが重視される。
ユーザーはブロックチェーン上で匿名でやり取りすることが多い。
現状と課題
Web2の時代には、データは「石油埋蔵量」のように貴重なものであり、大量のデータへのアクセスと取得は常に重要な課題であった。
Web3では、データのオープン化と共有化により、「石油が至る所にある」かのようになり、AIモデルのトレーニングデータとしてより多くのアクセスを容易にした。
しかし、このWeb3の「新しい石油」を処理するには課題も残る。
- データソースの複雑化
- 処理と更新性
- 分析(データ識別)
主にこの3つが大きな課題と言えるだろう。
データソースの複雑化
データソースの複雑化は、非常に厄介だ。
Web3データは、ブロックチェーンの台帳エントリーを除き、統一された生産・処理基準がなく、個々のチェーンやプロジェクトがイベント、ログなどのデータを定義し生成している。
例えば、UniswapやPancakeswapのような分散型取引所では、異なるデータ処理方法と基準を持ち、データ基準の検証と標準化のプロセスはデータ処理の複雑さに拍車をかけている。
そのため、それぞれのものに適応するためには多大な労力が必要。
専門家でないトレーダーが正確で信頼できるデータを特定することを困難にし、オンチェーン取引や投資の意思決定を複雑にしている。
処理と更新性
またオンチェーンデータは膨大かつ更新頻度も高い。
ブロックチェーンの動的な性質は、更新が秒単位やミリ秒単位で発生することから構造化データのタイムリーな処理が困難となり、データ処理の複雑さに拍車をかけている。
分析(データ識別)
オンチェーンデータは匿名性が高いため、データの識別に課題がある。
オンチェーンデータには、各アドレスを一意に特定するのに十分な情報が欠けていることが多く、オンチェーンデータとオフチェーンの経済的、社会的、法的な動きとの関連付けが困難である。
とはいえ、オンチェーンでの活動が現実世界の特定の個人や団体とどのように相関するかを理解することは、特定のシナリオにとって依然として重要である。
LLMがもたらす生産性の変化についての議論に伴い、AIを活用してこれらの課題に対処する能力は、Web3業界の中心的な焦点の一つとなっている。
従来のAIの活用
※従来のAIとLLMの違い
前提として従来のAI(deep learning)を応用するWeb3プロジェクトは複数存在。
ブロックチェーンデータ業界においてその重要性を証明しており、この分野にさらなるイノベーションと効率性をもたらしている。
- 0xScope
- クラスタ識別やアドレスとの関連付けに活用
- Nansen
- 価格予測にAIを活用。NFT市場の動向を洞察
- Trusta Labs
- シビル判定ツールの信頼性と安定性を強化
- Goplus
- セキュリティ情報を収集・分析し、リスクアラートを提供
- Footprint Analytics
- NFT取引、ウォッシュトレード活動、Botのスクリーニング分析に活用
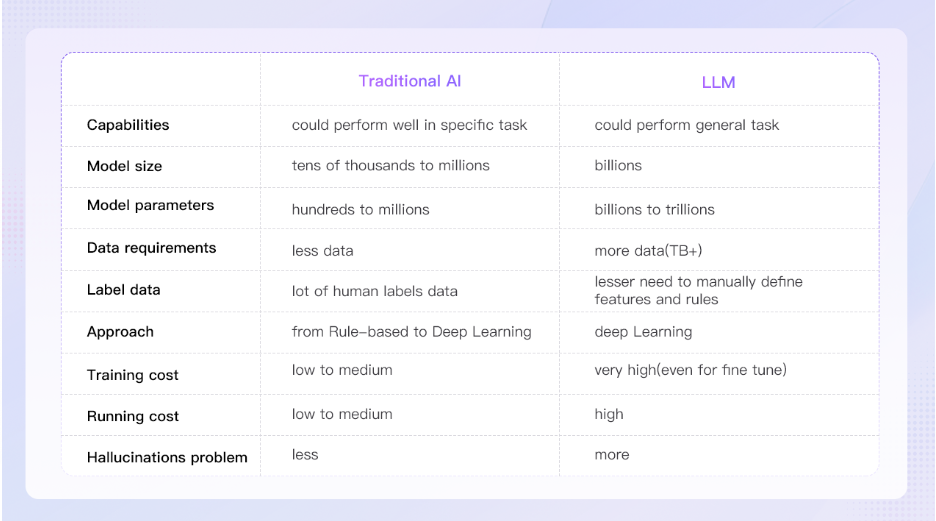
しかし、従来のAIは限られた情報に制約され、事前に定義されたアルゴリズムやルールを使用して事前に定義されたタスクを実行することに重点を置く。
対照的に、大規模言語モデル(LLM)は豊富な自然言語データから学習することで自然言語を捕捉・生成するため、複雑で大規模なテキストデータの処理に適している。
LLMの目覚ましい進歩に伴い、AIとWeb3データの統合に関する新たな考察や探求が登場している。
LLMの利点
LLMは、従来のAIと比較していくつかの利点を誇っている。
- スケーラビリティ
- 膨大なデータの取り扱いが可能に。
- テキスト分析や大規模なデータクレンジングなど、大規模な情報処理を必要とするタスクに有効。
- 適応性
- LLMは様々な領域の要件を学習し適応可能。
- 微妙な違いなどを学習することで、多様で多目的の課題に対応し、ブロックチェーン・アプリケーションを包括的にサポートする。
- 効率の向上
- LLMはタスクを自動化して生産性を高める。
- 従来は手作業で多大な労力とリソースを必要としていた作業を自動化し、生産性の向上とコスト削減を実現。
- タスクの分解
- 管理しやすいステップに分解して、特定のタスクの具体的な計画を作成。
- 膨大なブロックチェーンデータを扱う場合や、複雑なデータ分析タスクを実行する場合に非常に有益。
- アクセシビリティとユーザビリティ
- LLMはユーザーフレンドリーな対話が可能となる。
- 自然言語を活用することでSQL、R、Pythonなど複雑な専門知識なしにシステムデータにアクセスが可能。
- 開発等の簡略化も見込まれ、ブロックチェーンデータ産業の発展と普及に貢献可能。
LLMとWeb3データの融合
※LLMとWeb3データの融合
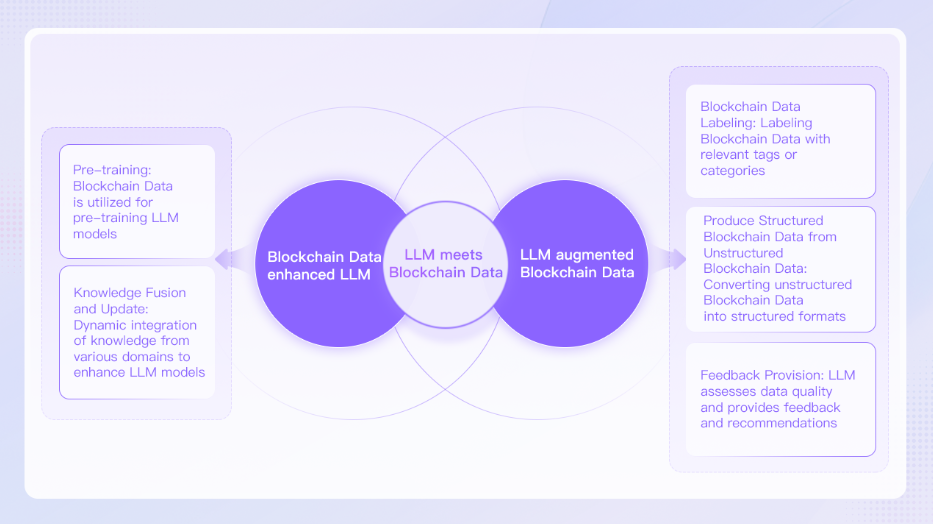
LLMのトレーニングは大量のデータが必要であり、データ内のパターンがモデルの基礎となる。
ブロックチェーンデータに埋め込まれた相互作用と行動パターンは、LLM学習の原動力となり、データの量と質もLLMの効果に直接影響する。
データはLLMが消費するだけのリソースではない。
データ作成に貢献し、フィードバックを提供することもできる。
例えば、データクレンジングやラベリングのようなデータ前処理においてアナリストを援助をすることができるだけでなく、ノイズを削除し価値ある情報を際立たせる構造化データを生成することも可能だ。
LLMを強化するテクノロジー
ChatGPTは、LLMの確かな問題解決能力を示すだけでなく、外部の能力をLLMの一般的な能力に統合するグローバルな探求にも火をつけている。
これには、一般的な能力(文脈の長さ、複雑な推論、数学、コード、マルチモーダリティなど)の強化や、外部能力の拡張(非構造化データの処理、より高度なツールの使用、物理世界との相互作用など)を含む。
現在ほとんどのアプリケーションは、プロンプトエンジニアリングとエンベッディング技術を使用した「RAG」に焦点を当てている。
既存のエージェントツールは、主にRAGの効率と精度を向上させることを目的としている。
以下がLLM技術に基づく主なアーキテクチャ。
- プロンプトエンジニアリング
- 目的の出力を生成させるためのプロセス。
- エンベッディング
- 根底にある関係やパターンを示すための数値表現。
- ドメイン固有の情報を導入することで、基礎となるモデルの一般性を保ちながら、より専門化され、特定のタスクに適応することが可能に。
- ファインチューニング
- 特定のモデルに追加学習を与えモデルの微調整を行う。
- リトレーニング
- 新しいデータセットを導入し、タスク等への適応性を高める。
- エージェントモデル
- タスクの分解や自己反省を行い複雑な現象を再現することを目指す。
これらは同じモデルを訓練し、改良する過程で一緒に使用することができる。
開発者は既存のLLMの潜在能力を十分に活用し、複雑化するアプリケーションのニーズを満たすために、さまざまなアプローチを試すことが可能だ。
この統合されたアプローチはモデルのパフォーマンスを向上させるだけでなく、Web3の急速な革新と進歩を促進する。
しかしながら、既存のLLMがWeb3の急速な発展において重要な役割を果たしてきた一方で、これらのモデル(例えば、OpenAI、Llama 2など)を十分に探求する前に、プロンプトエンジニアリングやエンベッディングなどのRAG戦略など簡単なところからベースモデルの微調整や再トレーニングを検討することが賢明であると言えるだろう。
LLMによるBCデータを作成の最適化
ではLMMがブロックチェーンデータの作成をどのように効率化するのか。
現状は主に以下3つのステップでデータの作成が行われる。
- データの整理
- 例外を処理し、標準化されたフォーマットに変換
- ビジネスデータの作成
- 標準化したデータを活用しビジネス・オペレーションや意思決定に関連する情報を作成
- ビジネス指標の計算と抽出
- ビジネスデータの情報(総トランザクションの月間成長率など)を活用し問題点などを洗い出す
もちろん最終的には問題点の抽出だけでなくトレンドの特定も。
現状は各ステップで非常に労力やコストがかかるものとなるが、LLMの活用でこれらは大きく改善されることが見込まれる。
データの整理
LLMは与えられたデータから特定の情報を抽出することが得意である。
そのため、ブロックチェーンの取引ログやイベントを分析し、取引金額、取引相手のアドレス、タイムスタンプなどの重要な情報を素早く得ることが可能に。
さらには一貫性のないデータや異常なデータを自動的に識別してクレンジングし、データの正確性と一貫性を確保し、データの品質を向上させる。
ビジネスデータの作成
オンチェーンデータをビジネスエンティティにマッピングすることが可能。
ブロックチェーンのアドレスを実際のユーザーや資産にリンクすることなどができ、業務の効率化が行えるようになる。
またツイートなどの情報から感情分析も可能に。
ポジティブ、ネガティブ、ニュートラルに分類することで、そのプロジェクトに対するユーザーの心理を探り、より深いデータを作成することができる。
ビジネス指標の計算と抽出
作成されたビジネスデータを活用しビジネスメトリクスを算出。
取引量、資産価値、市場シェアなど多角的にビジネスを評価することができるようになり、より使いやすいデータベースの作成が可能。
さらにこのデータの要約や説明を生成し、解釈可能性と合理的な意思決定を促進させることが期待される。
LLMの課題
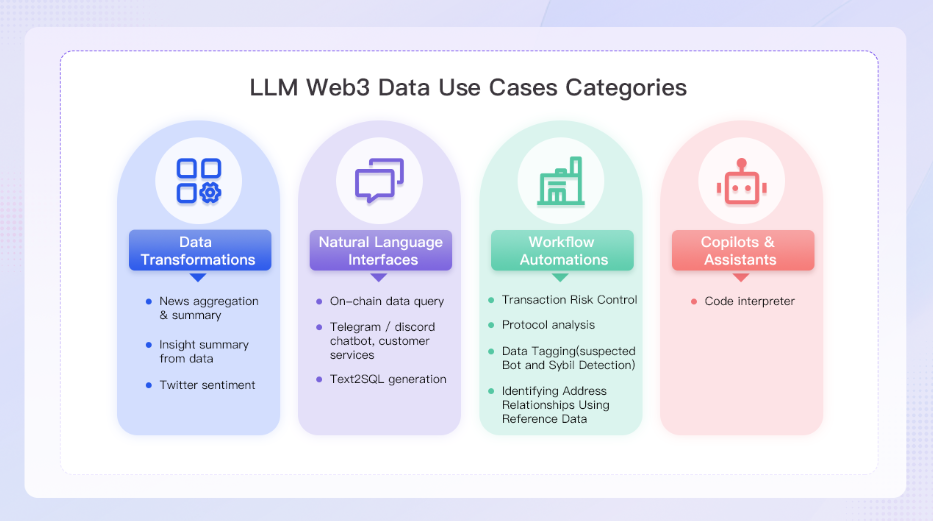
ただし、LLMが全てにおいて万能というわけではない。
確かにテキストの要約から説明、コードの生成等は便利な反面、LLMにはまだまだ多くの制約があり、確実に効率化ができるかと言えばNoだ。
- ハルシネーションの発現
- それっぽい嘘を出力することも
- 生成されたコードのバグ
- 生成したコードが必ずしも完璧というわけではない
- データラベリングの複雑さ
- 匿名化されたブロックチェーンデータは特に複雑
- モデルの調整の必要性
- 精度向上のために必要だが調整の専門性が高い
またこの他にもオンチェーンデータとの組み合わせもLLM1つでは完結しない。
この点については、すでに提供されているETLツール等を活用し、双方を組み合わせることで、より正確なデータ作成を可能とすることが現状の理想とされる。
現状のテーマ
現状のホットなテーマとしては、専門的な訓練を積んだLLMの活用だ。
LLMは通常、大量のテキストデータについて事前に訓練されているため、多様な非構造化テキスト情報の処理に長けている。
しかしWeb3を始め、様々な業界では、それに特化したデータが多く蓄積されている。
この蓄積されたデータを元に訓練を行った専門的なLMMを作成することが出来れば、より専門性の高い出力や情報の抽出などが可能。
さらに言えば、各企業が持つデータをカスタマイズすれば、その企業に特化したLMMも作成可能となるため、このような取り組みが行われることに期待したい。
LMMはAPIの活用も可能なため、このような特化したLMMも時期に出てくるだろう。

またLangChainなどの関連ツールを活用しLLM上にブロックチェーンデータソリューションを作成することも技術的には可能ではある。
しかしその場合にも課題は残る。
高品質なソリューションを作成するためには、ブロックチェーン技術とAIツールの仕組みの両方を深く理解し、効果的に統合する必要があることは言うまでもない。
こちらも重要なテーマでありながら、非常にシビアな課題と言えるだろう。
ただブロックチェーン分野やAI分野は急速に進化を遂げている。
特にAI分野では、AutoGPTやAutoGen、ChatGPT 4.0 Turboといった新興GPTフレームワークが登場しているが、これらも可能性のほんの一部に過ぎない。
ブロックチェーン、AIには十分な成長の余地があり、継続的な努力と革新が必要であるという事実を強調している。
LLMはすぐに活用するべきか
LLMの活用は慎重に行うことが推奨される。
もちろんこのソリューションが有効活用されれば、Web3データ業界にとっても有益なものとなるが、現状は過度な期待をすべきではない。
- 膨大な計算資源が必要
- 高いトレーニング費用
- トレーニング過程が不安定になる可能性
- 出力精度の不安定さ
このような問題もあることは留意すべきである。
過度な期待により、無理やりビジネスに組み込みがちではあるが、関連するリスクやLMMの活用に対する具体的なニーズの洗い出しは重要。
LLMは様々な領域で計り知れない可能性を秘めているが、開発者や研究者はLLMを適用する際には慎重を期し、オープンマインドな探索アプローチを維持しなければならない。
このアプローチにより、より適切な応用シナリオを確実に発見し、LLMの利点を最大限に引き出すことで、業界のさらなる進化が遂げられるであろう。
本レポートについて
本レポートは、Footprintの情報を元にコミュニティや弊メディアが一部加筆、編集を加えたものとなっています。
フットプリント・コミュニティは、世界中のデータと暗号の愛好家が、Web3、メタバース、DeFi、GameFi、あるいはブロックチェーンの発展途上の世界のその他の領域について理解し、洞察を得るために互いに協力し合う場所です。
ここでは、活発で多様な声がお互いを支え合い、コミュニティを前進させることができます。
データ掲載中!GameFi・NFTピックアップニュース
| 暗号資産(仮想通貨)のお得情報! | |
|---|---|
| キャンペーンまとめ | 取引所キャンペーン |
| 0円で始める投資術 | 無料で暗号資産を入手 |
| 無料でビットコイン | BTCが貰えるサービス |
| 無料でETHを獲得 | ETHが貰えるサービス |
| 即日買える取引所 | 購入まで一番早い取引所 |